從 2022 年底爆發的生成式 AI 熱潮,以及它所依賴的大型語言模型(LLM),肯定會對資料工程與資料科學產生重大的影響。這幾年我們團隊看到的商用版本 MLOps 平台解決方案供應商,正在急速轉向 LLM 的開發、調優與指示工程(Prompt Engineering)。
這個重大的轉折點將會進一步推升「非/半結構化資料」的蒐集、處理與應用。然而,這個相對陌生的領域,將為資料專案帶來前所未有的、艱鉅的挑戰。
如何更快速地調用所有載體的資料,讓 Open data Lake/Lakehouse 的議題瞬間冒出來。除了我們在本系列前幾篇都提到開源軟體專案 Apache Iceberg,Metadata Management 這個灶都還沒燒熱,就出現了更細緻的市場分隔—Data Version Control Infra(Data Versioning)。

圖片來源:https://lakefs.io/blog/the-state-of-data-engineering-2023/attachment/1200x630-lakefs-state-of-data-engineering-report/
這個 Data Versioning 的新興市場實在太新太新了!大約起於 2021 年 。而且關聯解決方案的吉祥物都可愛的要命!不愧是 Y & Z 世代的新創。

LakeFS 是一個開源專案,背後是一間新創公司 Treeverse。創辦人埃納特·奧爾 (Einat Orr) 和奧茲·卡茨 (Oz Katz) 分享 LakeFS 的任務:「作為處理大量資料的 Data Engineer,我們感到非常沮喪,因為我們的大量時間都花在重複的反應性任務上,例如:修復資料不一致、將資料回滾到之前的一致狀態,以及處理運算資源分配不均和浪費,造成更多資料副本產生,系統雜亂不堪難以維運。 我們決定編寫一個開源解決方案,為所有這些問題提供概念性解決方案。」
LakeFS 的目標是作為資料湖的版本控制系統,以類 Git 方式運作。 資料工程師可以使用它來建立資料的獨立版本,與其他團隊成員共用它們,並輕鬆地將變更合併到主分支中。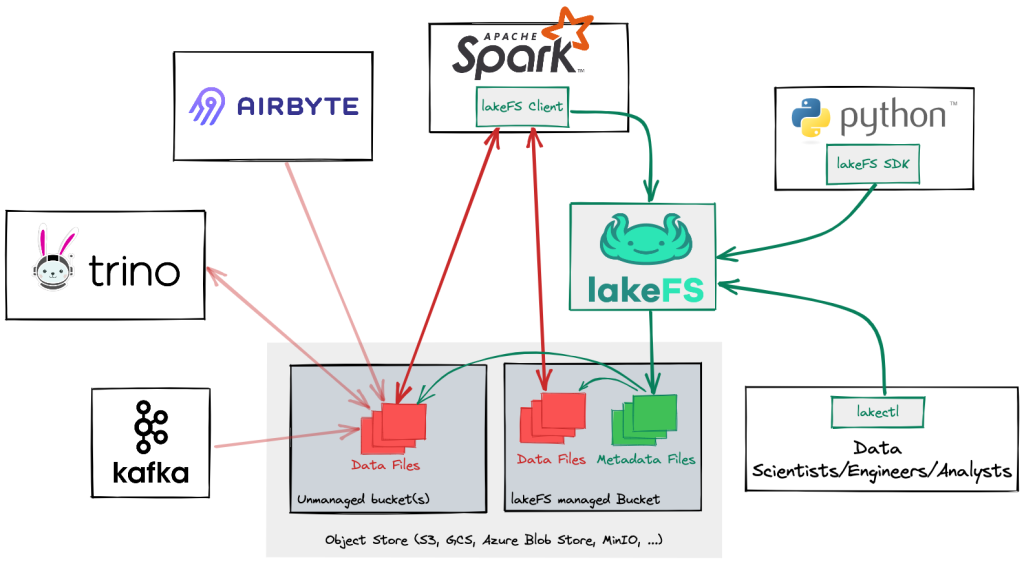
圖片來源:https://lakefs.io/wp-content/uploads/2023/07/what_is-1024x564.png

開源專案 Nessie 的目標也是作為資料湖的 Git 儲存庫,屬於 Data Infra 層。
追蹤各個資料檔案通常是手工業,Nessie 想讓資料工程師從這個艱苦的工作中解放。 Nessie 知道哪些資料檔案正在使用以及哪些資料檔案可以安全地刪除。而且 Nessie 並不會複製資料,而是對現有資料做註冊。
Nessie 為使用者提供所有相關資料集(表)始終一致的資料視圖。 資料的變更(例如來自批次作業的變更)獨立發生且完全隔離。 使用者不會看到任何不完整的更改。 完成所有變更後,所有變更都可以自動且一致地套用,並對使用者可見。
圖片來源:https://www.dremio.com/a-notebook-for-getting-started-with-project-nessie-apache-iceberg-and-apache-spark/
我還記得 BIG DATA LANDSCAPE 2017 中百花齊放的熱鬧場景。當時資料領域技術的細分市場,還是一些傳統的名詞,但是到了 2023 年開始出現一些奇妙的詞彙。
我個人觀察到趨勢就是 IT Infra, Data Infra, Data Pipeline, ML Pipeline 與 Data Governance 的整合,也是炬識科技正在前進的道路。這些領域的整合跨越了 IT, Data, Business Domain。
因此,我們正在強化團隊調適性積極蛻變,以預備這段旅程。所以我說,資料領域需要什麼都來點 Ops:DevOps, DataOps, MLOps, AIOps。


{kind=link}